
# 第一部分回顾:深度学习基础(Lecture2—Lecture4)
在进入卷积网络之前,先回顾前几讲建立的深度学习基础框架。
# 图像分类与线性分类器
第一步是定义问题:输入一张图像(展开为张量),输出一个分数向量,表示各标签与图像的匹配程度。通过权重矩阵 进行预测:
问题由此转化为:如何选择一个好的 ? 这便引入了损失函数。
# 损失函数
损失函数告诉我们:给定权重矩阵 与数据集,这个 在解决当前问题上表现如何。常用损失函数包括:
- 多分类 SVM 损失(Hinge Loss):
- Softmax 损失(交叉熵损失):
现在我们有了问题定义(线性分类器)和评判标准(损失函数),但还需要找到一个好的解决方案——这引出了优化。
# 优化
将优化环境想象成高维空间中的一个曲面:x 轴(或整个平面)上的每个点对应一组权重 ,y 轴是损失函数值。损失越高说明模型越差,所以优化的目标是让损失往下滑,在曲面的最低点附近找到一组权重。
常用优化算法沿以下路线演进:
| 方法 | 核心改进 |
|---|---|
| SGD | 用 mini-batch 梯度近似全量梯度,解决计算效率 |
| SGD + Momentum | 引入速度/惯性,冲过鞍点和局部极小值 |
| RMSProp | 逐参数自适应学习率,解决病态条件 |
| Adam | 动量 + 自适应学习率 + 偏差修正,全能选手 |
| AdamW | Adam + 解耦权重衰减,当前主流默认选择 |
# 线性分类器的局限
线性分类器本质上需要为每个类别总结出一个模板。当同一类别在特征空间中呈现多模态分布(如分布在两个相对象限中),单个模板无法同时覆盖——这正是线性分类器无法处理奇偶分布、同心圆等问题的根本原因。

# 神经网络的引入
将两个权重矩阵叠加,并在中间插入非线性激活函数:
这一简单的改动赋予了模型非线性分类能力。关键在于:如果去掉中间的 , 退化为单个矩阵 ,又变回线性分类器。堆叠任意多层线性变换,等价于一层线性变换——表达能力没有一丝提升。非线性激活函数的最核心作用永远是:引入非线性。
# 计算图与反向传播
为了优化模型参数,需要计算损失函数对每个权重的梯度。计算图正是为此而设计:它是一个有向无环图(DAG),节点是运算步骤,边是数据流。
- 前向传播:数据从左往右流,经过各中间节点,最终算出损失
- 反向传播:一旦算出损失,从右往左沿图回溯,使用链式法则自动计算每个节点的梯度
核心公式极为简洁:
重要的形状法则:上游梯度总是与输出形状相同,下游梯度总是与输入形状相同。维度分析即可推导出任何张量运算的反向传播,无需死记公式。
# 完整流程总结
对于任意待解决的问题:
- 将输入编码为张量
- 写出计算图,计算输出张量
- 收集数据集,定义损失函数
- 使用梯度下降优化损失,通过反向传播自动计算梯度
这套流程基本支撑了所有深度学习应用。
# 图像特征表示 Image Features
# 为什么需要特征?
实际上,神经网络的输入不一定非得是原始像素。我们可以定义一些其他类型的函数来提取特征——将原始图像的像素值转化为更有意义的表示,再送入线性分类器。
两个经典的例子:
颜色直方图 Color Histogram:将所有像素按颜色值归类到具体的桶(bucket)中,只统计颜色分布,完全忽略空间位置信息。比如一张蓝天的图片,蓝色像素占比会远高于其他颜色。

定向梯度直方图 Histogram of Oriented Gradients (HOG):丢弃颜色信息,只关注图像中的结构信息——计算每个局部区域中边缘的方向分布。它关注的是"这个区域有怎样的边缘走向",而不是"这个区域是什么颜色"。

# 特征提取 + 分类器的组合范式
在深度学习兴起之前,计算机视觉的主流范式是:
- 手动设计特征提取器(颜色直方图、HOG、SIFT 等)
- 将多种特征堆叠拼接成一个特征向量
- 将特征向量送入线性分类器(如 SVM)

好的特征表示需要大量领域知识和工程经验。问题在于:作为人类,很难手写完美的特征提取器——数据本身和端到端的学习往往能做得更好。
# 端到端神经网络
神经网络的思路完全不同:
- 输入:原始像素值
- 输出:预测分数
- 整个系统通过梯度下降从训练数据中自动学习所有参数
不需要手动设计特征——网络自己学习需要提取哪些特征。问题变成了:如何设计神经网络架构? 即决定运算符的序列和中间张量的大小。
# 从全连接层到卷积层
# 全连接层的局限
回顾全连接层(Fully Connected Layer):将 CIFAR-10 图像( 维)展开成一维向量,与权重矩阵 做矩阵乘法,得到 10 个类别的预测分数。
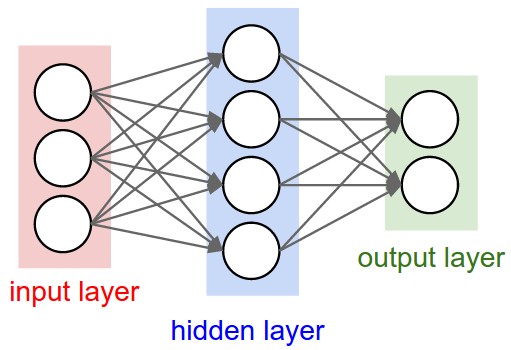
全连接层的底层原理是向量点积:两个向量方向接近时点积结果高,正交时结果为零(或很小)。每一行权重可视为该类别的"模板"。
致命的缺陷:将图像压扁成一维向量,完全损失了空间结构。一个像素与它上下左右的像素之间的空间关系在压扁后荡然无存——左邻像素和右邻像素在 3072 维向量中相隔 32 个位置,与一个完全无关的远处像素相邻。
# 如何尊重二维信息?
这就是卷积神经网络 CNN 的诞生原因。
CNN 的核心洞察:图像具有平移不变性。一只猫在图像偏左还是偏右的位置,它仍然是猫。全连接层会把"左上角的猫"和"右下角的猫"视为完全不同的输入模式,需要分别学习——这极其浪费。卷积层通过参数共享直接内置了这一归纳偏置:同一个滤波器在整个图像上滑动检测,无论特征出现在哪个位置。
# 卷积层 Convolutional Layer
# 基本思想:局部连接 + 参数共享
卷积层改变了全连接层的连接方式:
- 全连接层:每个输出神经元连接所有输入像素,权重数量
- 卷积层:每个滤波器只看输入的一小部分(局部感受野),同一个滤波器在整个图像上滑动并共享权重,权重数量仅
# 卷积运算的直观过程
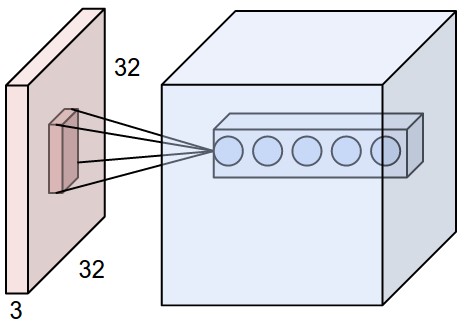
将一个 的小滤波器(filter / kernel)滑动到输入图像上的某个位置,计算该滤波器与该位置图像片段的逐元素乘积之和(即点积),得到一个标量。这个标量衡量了该位置与滤波器的"匹配程度"——值越大,说明该区域越符合滤波器检测的模式。
然后重复这个过程:将小滤波器滑动到输入图像上的每一个可能位置,计算并收集所有匹配分数,排列成一个二维网格 (称为激活图 Activation Map 或 特征图 Feature Map)。
单个滤波器只能检测一种模式(如边缘、纹理、颜色对比等)。要检测多种模式,需要多个滤波器:
- 第二个 滤波器做同样的事,生成另一张 的特征图
- 以此类推,添加任意数量的滤波器
- 将所有特征图沿深度方向堆叠,得到一个三维张量
每个卷积层还会添加一个偏置项(每个滤波器一个标量偏置),为非线性变换提供灵活性。
# 卷积层的定义
卷积层的关键运算符:
输入:一张图像 + 一组滤波器(随机初始化)
超参数:滤波器数量 (输出通道数)、滤波器尺寸
与全连接层相同,卷积层输出后必须接非线性激活函数(如 ReLU),否则多个卷积层的叠加仍等价于一层线性变换。
# 批量处理:四维张量
实际操作中我们处理的是一批图像(mini-batch):
| 张量 | 维度 | 含义 |
|---|---|---|
| 输入 | 一批图像(N 张) | |
| 滤波器 | 一组滤波器 | |
| 输出 | 一批输出特征图 |
# 空间维度计算
卷积后特征图的空间尺寸由三个因素决定:
不填充,步幅为 1:
例如: 的输入, 的卷积核 → 的输出。
带零填充 Zero Padding:
在图像边界外添加 圈零值像素,使输出尺寸可控:
如果需要输出尺寸与输入相同(),设置 。这也是 通常取奇数(3, 5, 7)的原因——保证填充为整数。
带步幅 Stride:
默认滤波器每次滑动 1 步。将步幅设为 可以加速卷积、减少计算量:
通用公式(三个参数同时出现,通常不引入膨胀):
其中 表示下取整——当 不能被 整除时,多余的边缘像素直接丢弃。

# 感受野 Receptive Field
为什么更深的层能"看到"更大的结构?
卷积层每一层的输出神经元只查看输入的本地区域。但经过堆叠后,感受野会被逐层放大:
- 第一层:一个神经元能看到 的原始输入区域
- 第二层:一个神经元能看到 的第一层输出区域 → 对应 的原始输入区域
- 第三层:对应 的原始输入区域
这种逐层扩大的效应使得:浅层学习边缘和纹理等局部特征,深层学习语义和整体结构等全局特征。

# 卷积
当 时,卷积核退化为一个"逐点"操作——它不混合空间信息,仅在通道维度上做线性组合。 卷积本质上是一个作用于每个像素位置的全连接层,常用于:
- 降维/升维:减少或增加通道数,相比于大核卷积极大幅度减少参数量
- 增加非线性:在 卷积后接 ReLU,在不改变空间尺寸的前提下增强模型表达能力
- 是 ResNet 瓶颈结构(Bottleneck Block)和 Inception 架构的核心构件
# 卷积的其他变体
除了标准的二维卷积,同一原理可以推广到不同维度:
| 类型 | 输入维度 | 卷积核维度 | 典型应用 |
|---|---|---|---|
| 1D 卷积 | 序列数据(文本、音频、时间序列) | ||
| 2D 卷积 | 图像处理 | ||
| 3D 卷积 | 视频分析、医学影像(CT/MRI) |
膨胀卷积 Dilated Convolution:在滤波器元素之间插入空洞(dilation rate ),在不增加参数的前提下指数级扩大感受野。例如一个 卷积核,膨胀率 时感受野等效于 。常用于语义分割和需要大感受野的密集预测任务。

分组卷积 Grouped Convolution:将输入通道分为 组,每组独立进行卷积,最后拼接输出。它将参数量和计算量同时降为 。分组卷积的思想最早在 AlexNet 中被用于多 GPU 训练,后来成为 MobileNet(深度可分离卷积)、ResNeXt 等高效/高性能架构的核心设计。
深度可分离卷积 Depthwise Separable Convolution:分组卷积的极端形式——,即每个通道分配一个独立的 滤波器。计算量约为标准卷积的 倍,是 MobileNet/Xception 等移动端网络的基石。
# 卷积层参数计算
以输入 ,卷积层 个 滤波器,步幅 1,无填充为例:
- 每个滤波器参数:(权重 + 偏置)
- 总参数量:
- 输出维度:
- 总连接数(乘加运算):
# 池化层 Pooling Layer
# 为什么需要池化?
步幅卷积是下采样的一种方式,但它需要学习参数且计算量较大。池化层提供了另一种更轻量的下采样方法——无参数、计算简单、天然带上采样能力。
# 最大池化 Max Pooling
最常见的池化方式:将特征图划分为多个不重叠区域(如 ),每个区域取最大值作为输出。

最大池化的两个核心作用:
- 降维:空间尺寸变为原来的一半( 池化),减少计算量和内存
- 引入平移不变性:小范围平移不会改变最大值的结果,网络对位置的微小变化更鲁棒
池化是一个早已存在的信号处理方法,只是被重新发现并整合进了深度学习管道中。
# 池化的设计约定
- 不使用填充:池化层的核心目的是降维,加零填充与其目的相悖
- 最常见设置: 区域、步幅 2(相当于无重叠的 窗口)
- 池化区域尺寸与步幅相等:默认就是不重叠的;如果步幅小于池化区域,就有重叠
# 平均池化 Average Pooling
取每个区域的平均值而非最大值。历史上曾广泛使用,但目前在分类网络中已大部分被最大池化取代。
一个重要区别:如果用平均池化取代最大池化,需要紧接着引入非线性激活函数,因为取均值是线性运算。而最大池化取的是 ,本身已经带非线性,不需要额外的激活。
# 池化层的形状公式
将池化视为一种"特殊的卷积":
其中池化窗口尺寸 通常等于步幅 ( 是最常见配置),因此:
# 其他池化方法
| 方法 | 说明 |
|---|---|
| 最大池化 Max Pooling | 取区域最大值,自带非线性,最常用 |
| 平均池化 Average Pooling | 取区域平均值,需要额外非线性激活 |
| 全局平均池化 Global Average Pooling | 取整张特征图的最大值,常用于 CNN 末端替代全连接层 |
| 全局平均池化 Global Average Pooling | 取整张特征图的平均值,将 压缩为 ,直接接分类器,极大减少参数量 |
# 输入尺寸不统一怎么办?
- 调整至同一大小:将所有输入图像 resize 到固定尺寸
- 填充:较小的图像用零或其他值填充至统一大小
- 自适应池化:在 CNN 末端使用全局平均池化(Global Average Pooling),无论输入特征图多大,输出固定为 ,自然消除了尺寸不统一的问题
# CNN 架构设计
# 典型架构模式
池化层与卷积层交替插入到网络中:
一个更具体的视觉模式:
核心规律:
- 空间尺寸逐步缩小:(通过卷积缩小 + 池化加速缩小)
- 通道数逐步增加:(从低级纹理到高级语义,需要更多模式来描述)
- 尾部使用全连接层进行分类

# 参数量分布规律
以经典架构为例,各层的参数量和计算量分布呈明显的"倒置"结构:
- 早期层:参数量极少(滤波器尺寸小),但计算量最大(空间尺寸大,卷积在大量空间位置上滑动)
- 后期全连接层:参数量巨大( 个输入神经元 × 分类数 = 大量参数),但计算量较小
这个规律驱动了此后多年 CNN 架构的设计:将全连接层替换为全局平均池化以削减参数,用更深的卷积层换取表达能力。
# 设计中的关键归纳偏置
卷积网络的两个核心假设(归纳偏置),使其天然适合处理图像:
- 局部性 Locality:像素之间的关系随空间距离增大而衰减——近处相关的概率远大于远处
- 平移不变性 Translation Invariance:一个特征无论在图像的哪个位置出现,都应当被同一滤波器检测到——参数共享保证了这一点
这两个假设不是从数据中学来的,而是被硬编码进网络结构中的设计选择。它们大幅减少了自由度——一个全连接层需要学习 个连接模式,而卷积层只需学习 个,同时天然过滤掉大量无意义的假关联。
# 代码实现
# 基本卷积运算的 NumPy 实现
import numpy as np
def conv2d_forward(X, W, b, stride=1, pad=0):
"""
X: 输入 (N, C_in, H, W)
W: 滤波器 (C_out, C_in, K_h, K_w)
b: 偏置 (C_out,)
"""
N, C_in, H, W_in = X.shape
C_out, _, K_h, K_w = W.shape
H_out = (H + 2 * pad - K_h) // stride + 1
W_out = (W_in + 2 * pad - K_w) // stride + 1
# 填充
X_padded = np.pad(X, ((0,0), (0,0), (pad,pad), (pad,pad)))
out = np.zeros((N, C_out, H_out, W_out))
for n in range(N):
for c in range(C_out):
for h in range(H_out):
for w in range(W_out):
h_start = h * stride
w_start = w * stride
patch = X_padded[n, :, h_start:h_start+K_h, w_start:w_start+K_w]
out[n, c, h, w] = np.sum(patch * W[c]) + b[c]
return out
def max_pool2d_forward(X, pool_size=2, stride=2):
"""
最大池化前向传播
X: 输入 (N, C, H, W)
"""
N, C, H, W_in = X.shape
H_out = (H - pool_size) // stride + 1
W_out = (W_in - pool_size) // stride + 1
out = np.zeros((N, C, H_out, W_out))
for n in range(N):
for c in range(C):
for h in range(H_out):
for w in range(W_out):
h_start = h * stride
w_start = w * stride
out[n, c, h, w] = np.max(
X[n, c, h_start:h_start+pool_size, w_start:w_start+pool_size]
)
return out# CNN 架构示例(类似 LeNet-5 风格)
class SimpleCNN:
def __init__(self):
# 第一卷积层:3 → 6 通道, 5x5 卷积核
self.conv1_W = np.random.randn(6, 3, 5, 5) * 0.01
self.conv1_b = np.zeros(6)
# 第二卷积层:6 → 16 通道, 5x5 卷积核
self.conv2_W = np.random.randn(16, 6, 5, 5) * 0.01
self.conv2_b = np.zeros(16)
# 全连接层:16*5*5 = 400 → 120 → 10
self.fc1_W = np.random.randn(400, 120) * 0.01
self.fc1_b = np.zeros(120)
self.fc2_W = np.random.randn(120, 10) * 0.01
self.fc2_b = np.zeros(10)
def forward(self, X):
# 输入 X: (N, 3, 32, 32)
# Conv1: (N,3,32,32) → (N,6,28,28)
out = conv2d_forward(X, self.conv1_W, self.conv1_b)
out = np.maximum(0, out) # ReLU
# Pool1: (N,6,28,28) → (N,6,14,14)
out = max_pool2d_forward(out, pool_size=2, stride=2)
# Conv2: (N,6,14,14) → (N,16,10,10)
out = conv2d_forward(out, self.conv2_W, self.conv2_b)
out = np.maximum(0, out) # ReLU
# Pool2: (N,16,10,10) → (N,16,5,5)
out = max_pool2d_forward(out, pool_size=2, stride=2)
# Flatten: (N,16,5,5) → (N,400)
N = out.shape[0]
out = out.reshape(N, -1)
# FC1: (N,400) → (N,120)
out = out.dot(self.fc1_W) + self.fc1_b
out = np.maximum(0, out) # ReLU
# FC2: (N,120) → (N,10)
scores = out.dot(self.fc2_W) + self.fc2_b
return scores# Convolution Summary
| 概念 | 说明 |
|---|---|
| 卷积层 | 局部连接 + 参数共享,保留空间结构 |
| 滤波器 | 的小张量,每个滤波器学习一种模式 |
| 输出维度 | |
| 参数量 | ,与输入空间尺寸无关 |
| 步幅 | 控制滑动步长,影响输出尺寸和计算量 |
| 零填充 | 控制边界效果, 可保持尺寸不变 |
| 感受野 | 堆叠卷积层后逐层扩大,深层学习全局结构 |
| 卷积 | 通道维度上的线性组合,用于升降维和增加非线性 |
| 膨胀卷积 | 不增加参数的前提下扩大感受野 |
| 分组卷积 | 分通道独立卷积,减少参数量和计算量 |
# Pooling Summary
| 概念 | 说明 |
|---|---|
| 池化层 | 轻量级下采样,无参数,降低空间尺寸和计算量 |
| 最大池化 | 最常用,自带非线性,引入平移不变性 |
| 平均池化 | 需要额外非线性激活,已被最大池化大量取代 |
| 典型设置 | 窗口,步幅 2,无填充 |
| 全局平均池化 | 将 压缩为 ,替代全连接层 |
| 位置 | 与卷积层交替插入:CONV-ReLU-POOL 循环模式 |
# 声明
本blog由Yumengmeng基于2025春季李飞飞斯坦福CS231n计算机视觉课程的视频内容结合Claude Code抓取网上开源笔记进行美化与排版,仅供个人复习使用。