
# 从线性分类器到神经网络
# 回顾:线性函数
线性分类器的核心公式:
其中 ,。D 是输入维度,C 是类别数量(输出标签数量)。
在 Lecture 2 中我们看到,线性分类器每类只能学习一个模板,面对多模态分布、同心圆等问题完全无能为力——你无法用一条直线分开两个交替占据四个象限的类别。
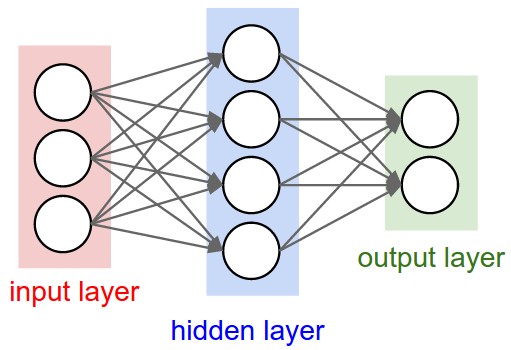
# 双层神经网络
神经网络在线性分类器的基础上,在输入和输出之间插入了一个隐藏层:
其中:
- — 输入向量
- — 第一层权重,将输入映射到 H 维隐藏空间
- — 第二层权重,将隐藏表示映射到 C 个类别得分
- H — 隐藏神经元数量,是一个超参数
权重矩阵的维度必须保持一致性:D → H → C,矩阵乘法才能正确执行。
# 为什么要引入非线性?
这是整个神经网络设计中最关键的问题。
如果去掉中间的 ,两层网络退化为:
存在一个 使得 ,又变回了线性分类器。堆叠任意多层线性变换,等价于一层线性变换——无论加多少层,表达能力没有任何提升。
非线性激活函数的作用是从一个空间变换到另一个空间,使原本线性不可分的数据在新空间中变得线性可分。隐藏层中的每个神经元可以理解为最终输出标签的某一部分"特征模板"——比如一个神经元学会检测"猫耳朵",另一个检测"猫眼睛",最终组合起来做出分类决策。
# 激活函数 Activation Functions
除了 (ReLU),常见的激活函数还包括:
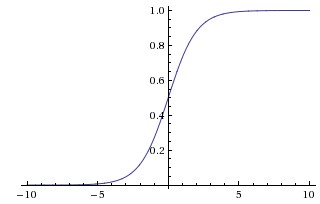
# Sigmoid
将值压缩到 (0,1);容易导致梯度消失——两端饱和区梯度趋近于零。梯度公式简洁:。
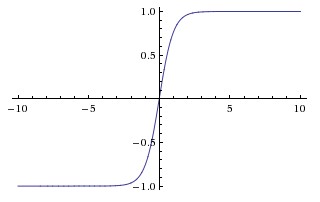
# Tanh
将值压缩到 (-1,1),零中心化优于 Sigmoid,但同样存在梯度消失问题。
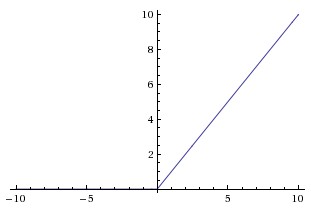
# ReLU
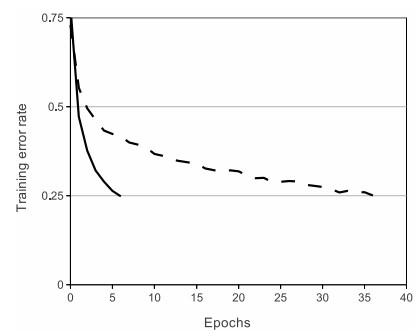
计算高效,大多数场景的默认首选(CNN、Transformer 均适用);缺点是有"死亡神经元"问题——权重一旦归零后永不激活。Krizhevsky 等人 2012 年的实验表明,ReLU 的收敛速度远超 Tanh:
# Leaky ReLU
负区间保留微小梯度,缓解死亡神经元问题。
# ELU
负区间平滑,输出均值接近零,训练更稳定但计算量稍大。
# GELU 与 SILU (Swish)
GELU 是 Transformer 架构的标配激活函数(BERT、GPT 均使用);SILU/Swish 是 GELU 的近似,在某些视觉任务中性能更优。
# 选择建议
- ReLU — 默认起点,大部分 CNN 场景首选
- GELU / SILU — 现代 Transformer 架构的主流选择
- Sigmoid / Tanh — 基本不用于隐藏层(梯度消失严重),仅偶见于输出层或门控机制
- 激活函数最核心的作用永远是:引入非线性
# 一个完整的双层神经网络
大约 20 行代码即可构建。分为四步:
# 第一步:定义模型
import numpy as np
# 超参数
N = 100 # 样本数
D = 3072 # 输入维度(如 CIFAR-10: 32×32×3)
H = 100 # 隐藏神经元数量
C = 10 # 输出类别数
# 随机生成数据(仅示例)
X = np.random.randn(N, D)
y = np.random.randint(0, C, N)
# 初始化权重:小随机数 × 缩放因子
W1 = np.random.randn(D, H) * 0.01
b1 = np.zeros(H)
W2 = np.random.randn(H, C) * 0.01
b2 = np.zeros(C)# 第二步:前向传播 Forward Pass
# 隐藏层:线性变换 + ReLU 激活
h = X @ W1 + b1 # [N, H]
h_relu = np.maximum(0, h) # ReLU
# 输出层:线性变换得到得分
scores = h_relu @ W2 + b2 # [N, C]
# Softmax 交叉熵损失
exp_scores = np.exp(scores - np.max(scores, axis=1, keepdims=True))
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 数据损失:负对数似然
loss = -np.mean(np.log(probs[np.arange(N), y]))
# 正则化损失:L2
reg = 0.001 * (np.sum(W1**2) + np.sum(W2**2))
total_loss = loss + reg# 第三步:反向传播 Backward Pass
# Softmax 梯度
dscores = probs.copy()
dscores[np.arange(N), y] -= 1
dscores /= N
# W2 和 b2 的梯度
dW2 = h_relu.T @ dscores + 2 * 0.001 * W2 # 包含正则化梯度
db2 = np.sum(dscores, axis=0)
# 反向传播通过 ReLU:只路由到激活的神经元
dh = dscores @ W2.T
dh[h <= 0] = 0 # ReLU 反向:h≤0 的位置梯度为零
# W1 和 b1 的梯度
dW1 = X.T @ dh + 2 * 0.001 * W1
db1 = np.sum(dh, axis=0)# 第四步:梯度下降更新
learning_rate = 1e-3
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
W2 -= learning_rate * dW2
b2 -= learning_rate * db2# 模型容量与正则化
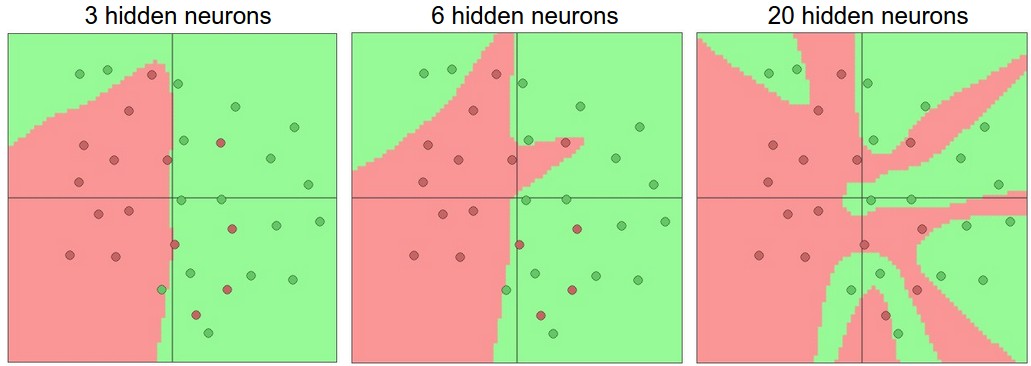
更多的神经元 = 更强的学习能力 = 更复杂的决策边界。但容量过大必然导致过拟合——模型记住了训练数据的噪声而非真实规律。
实践中更推荐的做法是:
优先调整正则化超参数,而非缩减模型规模。
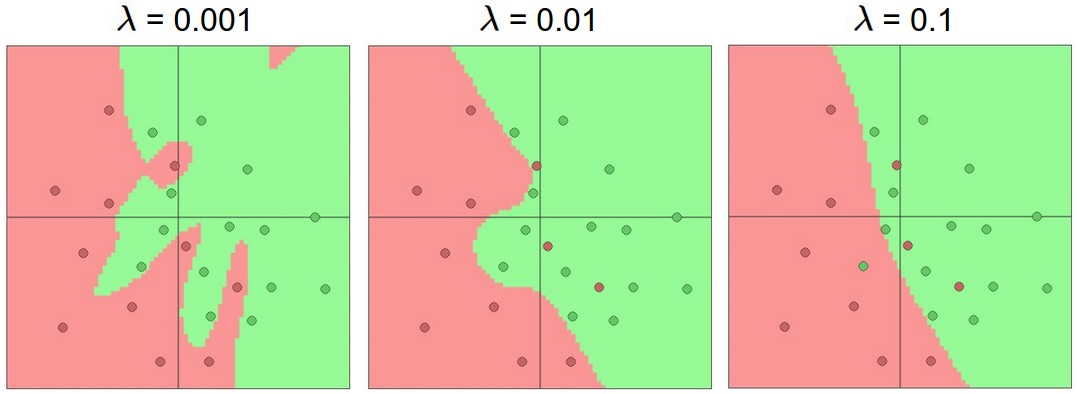
一个容量足够大 + 正确正则化的网络,通常优于一个容量刚好合适的网络。正则化强度 是关键调节旋钮:
- 过大 → 权重被过度压制 → 欠拟合
- 过小 → 模型自由度过高 → 过拟合
- 通过验证集调参找到最佳值
损失函数的完整组成(以双层网络为例):
# 计算图与反向传播
# 什么是计算图?
计算图是一个有向无环图(DAG),节点是运算步骤(加法、乘法、max、sigmoid 等),边是数据流(标量、向量、矩阵)。通过计算图,我们可以系统化地应用链式法则,自动计算任意复杂函数的梯度——这就是 PyTorch、JAX 等框架自动微分的核心原理。
反向传播的核心机制非常简单:每个节点收到上游传来的梯度,乘以自身的局部梯度(输出对输入的导数),然后把结果传递给下游。整个过程完全局部化,每个节点独立运作。
计算图上的反向传播,本质就是链式法则的递归应用。根据输入 的维度,分成三种情况: 是标量时导数是标量, 是向量且 是标量时导数是向量(梯度), 和 都是向量时导数变成雅可比矩阵。
# x 是标量,y 是标量 → 导数也是标量
和 以及所有中间变量都是标量,导数就是普通的 。最基础的情形。
经典例子 ,设 :
前向:,
反向(从 开始):
| 步骤 | 计算 | 结果 |
|---|---|---|
| 3 | ||
| -4 | ||
| -4 | ||
| 同理 | -4 |
在这个最简单的例子中,三种基本门已经展现出了各自的"性格":
- Add 门:分发器。上游梯度原封不动传给两个输入(局部梯度恒为 1)
- Multiply 门:交换器。,梯度乘以"另一个输入的值"。这意味着如果乘法门的一个输入很小、另一个很大,梯度分配会严重失衡——小输入得到极大梯度,大输入得到极小梯度。这也是数据预处理影响训练稳定性的根本原因
- Max 门:路由器。梯度只流向前向传播中值更大的那个输入,另一个得 0
当同一个变量被多次使用时(即计算图中出现分支),来自各条路径的梯度需要累加(+= 而不是 =),这是多变量链式法则的直接推论。
Sigmoid 函数 可以拆解为多个基本门(add → multiply → exp → add → reciprocal),但其局部梯度有简洁的闭式形式:
将整个 sigmoid 打包成一个"复合门"能大幅简化计算图:
# 前向
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid 复合门
# 反向:一行公式得到梯度
ddot = (1 - f) * f # σ'(x) = (1-σ)σ
dx = [w[0] * ddot, w[1] * ddot]
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot]# x 是向量,y 是标量 → 导数是向量
这是实际神经网络中最常见的情形—— 是一个向量(比如隐藏层激活值 ),损失 是标量。此时 变成一个与 同形的向量,每个分量 表示改变 对最终损失的影响。
核心原则: 的形状永远与 完全相同。这是向量化反向传播的第一性原理,后面所有推导都以此为出发点。
对于 ,, 为标量:
这里 是 Jacobian 矩阵(), 是梯度向量( 维)。但实际上我们几乎从不显式构造 Jacobian——一个 的 Jacobian 就有 100 万个元素,而实际网络的维度远大于此。
以 ReLU 为例:,。它的 Jacobian 是一个 的对角矩阵——对角线上要么是 0()要么是 1(),所有非对角元素全是 0。所以反向传播直接简化为逐元素条件判断:
dh = dscores @ W2.T # 上游梯度 [N, H]
dh[h <= 0] = 0 # 只传给激活了的神经元,无需构造矩阵# x 是向量,y 是向量 → 导数是雅可比矩阵(重点)
当 和 都是向量时, 变成一个矩阵——雅可比矩阵(Jacobian),形状为 ( 是 的维度, 是 的维度)。但实际中我们几乎从不显式构造它,而是利用稀疏性绕过。
以全连接层 为例—— 是 的矩阵, 是 , 是 :
- :,:,:
- 已知上游梯度 ,形状也是 (与 一致)
不需要死记公式。维度分析法四步就能推出来:
推导 :目标形状 (与 一致)。手上有的矩阵: 和 。唯一能拼出 的组合:。
推导 :目标形状 。。
用代码写出来就两行:
dW = X.T @ dY # [D, N] @ [N, M] = [D, M] ✓
dX = dY @ W.T # [N, M] @ [M, D] = [N, D] ✓观察这两个公式:它们正是乘法门"交换变量"特性在矩阵层面的体现——梯度传到 时乘以 ,传到 时乘以 。整个过程没有构造任何完整 Jacobian(那个尺寸会是 ,根本放不下内存)——这正是深度学习能在千万级参数上高效训练的根本原因。
值得一提的是,这个维度分析技巧适用面非常广:全连接层、卷积层、注意力层、Einsum……任何张量运算的反向传播,只要记住"梯度形状 = 变量形状",逆向拼维度就能推导出正确答案。
# 实践要点
- 分阶段计算:把复杂函数拆成简单中间变量,每个独立求导,链式组合
- 缓存前向值:反向需要前向的中间结果,别重复算
- 分支处用
+=:同一变量被多次使用时,梯度必须累加 - 梯度形状 = 变量形状:所有向量化反向传播的推导起点
- 先数值梯度检查,再切解析梯度:调试时用有限差分验证实现正确性
class MultiplyGate:
def forward(self, x, y):
self.x, self.y = x, y # 缓存
return x * y
def backward(self, dout):
return self.y * dout, self.x * dout # 交换 + 乘上游梯度每个运算模块写好 forward() 和 backward(),就能像搭积木一样组合出任意复杂网络——这正是 PyTorch 等框架的设计哲学。
# 声明
本blog由Yumengmeng基于2025春季李飞飞斯坦福CS231n计算机视觉课程的视频内容结合Claude Code抓取网上开源笔记进行美化与排版,仅供个人复习使用。