
# 正则化 Regularization
# 为什么需要正则化?
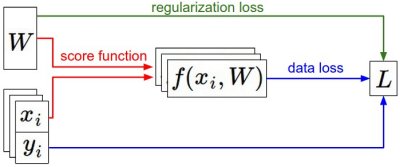
在 Lecture 2 中我们定义了完整的损失函数:
其中第一项是数据损失 Data Loss,衡量模型在训练集上的预测误差;第二项是正则化项 Regularization Term。
如果只最小化数据损失,模型会倾向于过拟合 Overfitting——过度记忆训练数据中的每一个细节、噪声和无用特征,导致在训练集上表现极好(loss 接近零),但在从未见过的测试数据上表现糟糕。正则化的核心目的就是防止模型在训练数据上"表现得太好",从而提升泛化能力。
这背后是奥卡姆剃刀原则 Occam's Razor:在所有能解释同一现象的假设中,最简单的那个往往是最好的。正则化通过惩罚复杂模型,引导优化过程偏好简单、可泛化的解。
# 正则化的三个核心作用
- 表达偏好:在多个都能拟合训练数据的 W 中,正则化表达了我们对"什么样的权重更好"的先验偏好(例如权重应该分散、不应该过大)
- 提升泛化:降低模型复杂度,减少过拟合,让模型在未知测试数据上表现更好
- 稳定优化:L2 正则化为损失函数添加二次曲率,使优化曲面更加"碗状",梯度下降更容易找到好的解
超参数 控制正则化的强度:
- 过大 → 模型过于简单 → 欠拟合 Underfitting(连训练数据都学不好)
- 过小 → 模型过于复杂 → 过拟合 Overfitting(记住了训练数据的噪声)
- 需要通过验证集手动调整,是训练时必须调优的重要超参数
# L1 正则化(Lasso)
公式:
L1 正则化将所有权重的绝对值和作为惩罚项。L1 的惩罚是线性增长的,这导致一个关键特性:稀疏性 Sparsity——优化过程会主动将大部分权重推向精确的零值,只保留少数真正重要的非零权重。
为什么 L1 产生稀疏解? 考虑一个简单场景:损失函数是一个二次曲面,正则化是 L1 的菱形约束区域。最优解往往落在菱形的顶点(坐标轴上),此时某些权重精确为零。而 L2 的约束区域是圆形,最优解通常落在圆内部某处,权重都不为零。这就是 L1 天然适合特征选择 Feature Selection的原因。
代码实现:
def l1_regularization(W, lambda_reg):
"""
L1 正则化损失
"""
reg_loss = lambda_reg * np.sum(np.abs(W))
return reg_loss
def l1_gradient(W, lambda_reg):
"""
L1 正则化的梯度:d(R)/dW = lambda * sign(W)
注意在 W=0 处不可导,实践中使用次梯度 subgradient
"""
dW = lambda_reg * np.sign(W)
return dW# L2 正则化(Weight Decay / Ridge)
公式:
L2 正则化将所有权重的平方和作为惩罚项。由于平方函数的特性——权重值越大惩罚越重(平方增长),优化过程会倾向于让所有权重都保持较小的值,并且均匀分散到各个维度。
直观例子:假设输入向量 ,考虑两组权重:
- ,与 x 的内积 = 1,L2 惩罚 = 1
- ,与 x 的内积 = 1,L2 惩罚 = 0.25
两组权重在分类效果上完全相同(内积都是 1),但 L2 正则化强烈偏好 ,因为它利用了所有输入维度,权重分布更均匀、每个值更小。这种"不把鸡蛋放在一个篮子里"的策略让模型对输入噪声更鲁棒。
代码实现:
def l2_regularization(W, lambda_reg):
"""
L2 正则化损失
W: 权重矩阵
lambda_reg: 正则化强度超参数
"""
reg_loss = lambda_reg * np.sum(W * W)
return reg_loss
def l2_gradient(W, lambda_reg):
"""
L2 正则化的梯度:d(R)/dW = 2 * lambda * W
"""
dW = 2 * lambda_reg * W
return dW# Elastic Net
公式:
Elastic Net 将 L1 和 L2 线性组合,同时享受两者的优点:L2 的权重收缩与稳定性 + L1 的稀疏性与特征选择。通过调整 参数来控制两者的相对强度。
在实际深度学习中,单纯的 L1/L2 权重正则化使用频率逐渐降低,更多被以下结构化正则化方法取代:
- Dropout:训练时随机"丢弃"(置零)一部分神经元,强制网络学习冗余表示,防止神经元之间形成过度依赖
- Batch Normalization:对每一层的激活值进行归一化,稳定数据分布,本身自带轻微正则化效果
- 数据增强 Data Augmentation:对训练图像进行随机翻转、裁剪、颜色抖动等变换,相当于免费扩大了训练集
- Stochastic Depth:训练时随机丢弃整层网络,强迫梯度通过不同的子网络传播
# 优化 Optimization
# 优化问题概述
在确定了损失函数之后,下一个问题是:如何找到使损失最小的权重 W? 这就是优化问题。
损失函数可以想象成一个高维曲面(比如 CIFAR-10 线性分类器有 个参数),我们的目标是走到这个曲面的最低点。但盲目地走显然不可行——下面首先来看为什么"随机猜测"行不通。
# 策略零:随机搜索 Random Search(反面教材)
最 naive 的想法:随机生成很多组权重,每组都算一下损失,选损失最小的那个。
best_loss = float('inf')
best_W = None
for _ in range(1000):
W = np.random.randn(10, 3073) * 0.001 # 随机生成权重
loss = compute_loss(W, X_train, y_train)
if loss < best_loss:
best_loss = loss
best_W = W在 CIFAR-10 上,随机搜索的最好结果仅为 15.5% 准确率,而当时最优方法已达到约 95%。随机搜索在高维空间中完全没有方向感——这就像在撒哈拉沙漠里随机扔一个飞镖,指望恰好命中某个特定沙粒。
我们需要利用损失曲面的几何信息来指导搜索方向。 这就引出了梯度下降。
# 梯度下降法 Gradient Descent
# 介绍
梯度下降是整个深度学习优化的基石,所有后续高级优化器(SGD、Momentum、Adam)本质上都是它的变体或改进。
# 思路
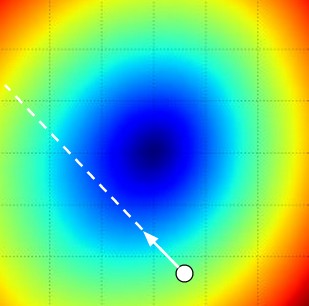
想象你站在一片山区,四周被浓雾笼罩,完全看不见山脚在哪里。你唯一能感知的是脚下地面的坡度——往哪个方向走是下坡。梯度下降的策略很简单:每一步都沿着当前最陡的下坡方向走一小段距离,重复这个过程直到地面变平(梯度趋近于零)。
梯度是导数在多维空间中的推广,它是一个向量,每个分量是损失函数对对应参数的偏导数。梯度指向函数值增长最快的方向,所以我们沿着负梯度方向走就是下降最快。
# 原理
一维情况:导数 ,表示函数在该点的瞬时变化率。
多维情况:梯度 ,是一个 n 维向量。
更新公式:
其中 是学习率 Learning Rate,控制每一步走多远,是最关键的超参数之一。
# 数值梯度 vs 解析梯度
计算梯度有两种方式:
数值梯度 Numerical Gradient(用定义近似):
def eval_numerical_gradient(f, x, h=1e-5):
"""使用中心差分法计算数值梯度"""
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
idx = it.multi_index
old_val = x[idx]
x[idx] = old_val + h
fxh1 = f(x)
x[idx] = old_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = old_val
it.iternext()
return grad- 优点:简单、直观,不需要推导
- 缺点:极其缓慢(每个参数都要算两次前向传播),精度受 h 选择影响;仅用于梯度检查,不用于训练
解析梯度 Analytic Gradient(微积分推导):
直接从损失函数公式推导出精确的梯度表达式。例如,SVM 损失对 W 的梯度:
- 优点:精确、快速(一次计算得到所有梯度)
- 缺点:推导过程容易出错
实践中的铁律:训练时使用解析梯度;调试时使用数值梯度做梯度检查 Gradient Check——如果两者差异过大,说明解析梯度的公式或实现中有 bug。
# 基本梯度下降的代码实现
def gradient_descent(X, y, W_init, learning_rate, num_iters):
"""
全量梯度下降(Batch Gradient Descent)
每次迭代使用全部训练数据计算梯度
"""
W = W_init.copy()
loss_history = []
for i in range(num_iters):
# 计算在整个训练集上的梯度
scores = X.dot(W)
loss, dW = svm_loss(scores, y) # 包含数据损失 + 正则化损失的梯度
# 沿负梯度方向更新
W -= learning_rate * dW
loss_history.append(loss)
return W, loss_history全量梯度下降的致命问题:当训练集很大时(如 ImageNet 有 120 万张图),每走一步都需要计算全部数据的梯度,计算代价高到无法接受。
# 随机梯度下降 Stochastic Gradient Descent (SGD)
# 介绍
SGD 是深度学习中最基础的实用优化算法。它用一个关键洞察解决了全量梯度下降的效率问题:不需要精确梯度,近似梯度就够了。
# 思路
与其每次用全部 N 个样本计算精确梯度,不如随机抽取一小批(mini-batch,通常 32/64/128/256 个样本),用这批样本的梯度作为整体梯度的无偏估计。这样每一步的计算量从 O(N) 降到了 O(batch_size),使得大规模数据上的训练成为可能。
术语澄清:"SGD" 在实际使用中几乎总是指 Mini-batch SGD(小批量随机梯度下降),而不是每次只用一个样本的极端版本。
# 原理
全量梯度下降的更新公式是:
SGD 将其替换为对 mini-batch 的近似:
其中 是 mini-batch 大小, 是随机采样的索引。一个 Epoch 定义为遍历整个训练集一次(即所有 mini-batch 的梯度更新加起来覆盖了全部数据)。
# SGD 面临的三大挑战
尽管 SGD 解决了计算效率问题,但它本身存在三个核心缺陷:
挑战一:病态条件 Ill-Conditioning
损失曲面的曲率在不同方向差异巨大——某些方向陡峭(梯度大),某些方向平坦(梯度小)。SGD 在陡峭方向上来回震荡(zigzag),在平坦方向上却几乎无法前进。这就像一个窄长的峡谷:你沿着峡谷壁来回弹跳,但沿着谷底的推进却极其缓慢。
挑战二:鞍点 Saddle Points
在高维空间中,鞍点的数量远超局部极小值。鞍点处梯度等于零,但有些方向是上坡(最小值)、有些方向是下坡(最大值)——典型的例子是 ,在原点沿 x 方向是极小值,沿 y 方向是极大值。普通 SGD 遇到鞍点时梯度趋近于零,更新几乎停滞,但实际上并非真正的最优点。
挑战三:梯度噪声 Gradient Noise
每个 mini-batch 计算出的梯度都是整体梯度的含噪估计——不同的 mini-batch 给出略有不同的梯度方向和大小。这种随机性使得 SGD 的更新路径始终在"抖动",收敛过程不够平滑。
不过梯度噪声也有一个意外的好处:它有时能帮助 SGD 从浅的局部极小值中跳出来,而这在全量梯度下降中是不可能的。
# 代码实现
def sgd(X, y, W_init, learning_rate, batch_size, num_epochs):
"""
小批量随机梯度下降
"""
N = X.shape[0]
W = W_init.copy()
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
# 每个 epoch 开始时打乱数据顺序
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
# 取一个 mini-batch
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
# 计算 mini-batch 梯度
scores = X_batch.dot(W)
loss, dW = svm_loss(scores, y_batch)
# 更新
W -= learning_rate * dW
loss_history.append(loss)
return W, loss_history# 带动量的随机梯度下降 SGD with Momentum
# 介绍
带动量的 SGD 是 SGD 的第一个重要升级。它在原始 SGD 的基础上引入了一个速度变量 velocity,让参数更新带有"惯性"。
# 思路
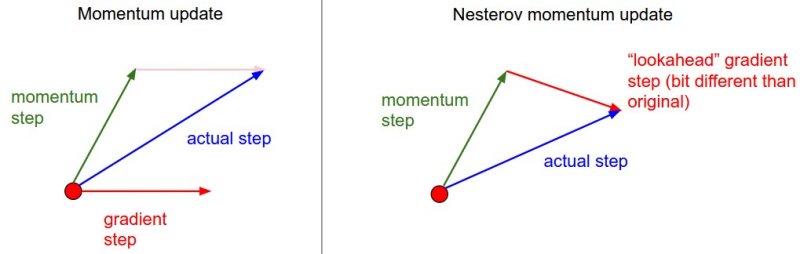
想象你把 SGD 的优化过程想象成一个小球在损失曲面上滚动。普通 SGD 的小球没有质量——每一步只看当前位置的坡度,走到哪算哪,非常容易在峡谷里来回震荡或被鞍点"卡住"。带动量的 SGD 赋予小球质量和惯性:它记住了之前运动的方向和速度,即使当前梯度很小甚至为零,积累的动量也能推动它继续前进,冲过鞍点和平坦区域。
同时,由于速度是历史梯度的加权平均,它自然地平滑掉了梯度噪声——单个 mini-batch 的随机波动被抹平,整体的前进方向更加一致和稳定。
# 原理
动量方法维护一个速度向量 v,每一步将其更新为历史速度与当前梯度的加权组合:
其中:
- (动量系数,又称 或 momentum)通常取 0.9 或 0.99
- 是历史梯度的指数加权移动平均 Exponential Moving Average
- 意味着当前速度约等于过去约 10 步梯度的加权平均
为什么动量能克服鞍点? 在鞍点处 ,如果是普通 SGD,更新直接停止。但带动量的 SGD 中:
速度不会立刻消失,而是以 的比例衰减,继续推动参数向前走。这就像球滚到了一个小凹陷处——纯靠坡度它出不来,但如果有速度,就能直接冲过去。
# Nesterov 加速梯度(NAG)
Nesterov 动量是标准动量的一个巧妙改进:先沿着速度方向"展望"一步,在那个位置计算梯度,而不是在当前位置算。这相当于在行动之前先"看一步"。
NAG 对于凸优化问题有更好的理论收敛保证,在非凸的深度学习实践中也往往比标准动量略好一些。
# 代码实现
def sgd_momentum(X, y, W_init, learning_rate, momentum, batch_size, num_epochs):
"""
带动量的随机梯度下降
momentum: 动量系数,典型值 0.9
"""
N = X.shape[0]
W = W_init.copy()
v = np.zeros_like(W) # 初始化速度为零
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
scores = X_batch.dot(W)
loss, dW = svm_loss(scores, y_batch)
# 核心:速度更新 + 参数更新
v = momentum * v + dW # 累积历史梯度
W -= learning_rate * v # 用速度(而非原始梯度)更新
loss_history.append(loss)
return W, loss_history
# Nesterov 动量版本
def sgd_nesterov(X, y, W_init, learning_rate, momentum, batch_size, num_epochs):
"""
Nesterov 加速梯度下降
"""
N = X.shape[0]
W = W_init.copy()
v = np.zeros_like(W)
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
# 在"前瞻"位置计算梯度
W_ahead = W - momentum * v
scores = X_batch.dot(W_ahead)
loss, dW = svm_loss(scores, y_batch)
v = momentum * v + learning_rate * dW
W -= v
loss_history.append(loss)
return W, loss_history# RMSProp
# 介绍
RMSProp(Root Mean Square Propagation)由 Geoff Hinton 在 Coursera 课程中提出,是自适应学习率方法的代表作之一。它解决了 SGD 最为人诟病的问题——在所有参数上使用同一个全局学习率。
# 思路
回到 SGD 面临的病态条件问题:某些参数方向的梯度一直很大(陡峭方向),某些方向的梯度一直很小(平坦方向)。对所有参数使用相同的学习率必然意味着——要么陡峭方向上震荡发散,要么平坦方向上寸步难行。
RMSProp 的核心思想:每个参数应该有自己专属的学习率。如果一个参数的梯度一直很大,就给它小步走(防止震荡);如果一个参数的梯度一直很小,就给它大步走(加速前进)。
具体做法是维护每个参数的梯度平方的指数移动平均,然后用这个平均值来逐元素缩放学习率——梯度大的方向被除以大数(步长变小),梯度小的方向被除以小数(步长变大)。
# 原理
其中:
- :梯度平方的指数移动平均,注意这里的乘法是逐元素乘法
- :衰减率,典型值 0.9 或 0.99,控制历史信息保留多久
- :极小常数(如 ),防止除零
为什么用指数移动平均而不是简单累加? RMSProp 的前身是 AdaGrad,它将所有历史梯度平方直接累加:
这导致 cache 单调递增、学习率单调递减,在非凸问题中会过早地把学习率压到零,让训练提前停滞。RMSProp 使用指数移动平均——旧信息逐渐"遗忘"、新信息权重更大——完美解决了这个问题。
# 代码实现
def rmsprop(X, y, W_init, learning_rate, decay_rate, batch_size, num_epochs, eps=1e-7):
"""
RMSProp 优化器
decay_rate: 梯度平方的衰减率 (rho),典型值 0.9 或 0.99
"""
N = X.shape[0]
W = W_init.copy()
cache = np.zeros_like(W) # 梯度平方的移动平均
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
scores = X_batch.dot(W)
loss, dW = svm_loss(scores, y_batch)
# 更新梯度平方的移动平均
cache = decay_rate * cache + (1 - decay_rate) * dW ** 2
# 逐元素自适应学习率
W -= learning_rate * dW / (np.sqrt(cache) + eps)
loss_history.append(loss)
return W, loss_history# Adam(Adaptive Moment Estimation)
# 介绍
Adam 由 Kingma 和 Ba 在 2015 年提出,是目前深度学习中使用最广泛的优化器。它将 Momentum(一阶矩/动量) 和 RMSProp(二阶矩/自适应学习率) 的思想优雅地结合在一起,既有动量带来的平滑加速能力,又有逐参数自适应学习率的鲁棒性。
Adam 几乎是所有项目的默认优化器——如果不知道该用什么,先用 Adam 通常不会错。
# 思路
Adam 同时维护两个指数移动平均:
- 一阶矩 :梯度的指数移动平均(如同动量),记录梯度的"方向"和"趋势"
- 二阶矩 :梯度平方的指数移动平均(如同 RMSProp),记录梯度的"波动幅度"
然后用 作为更新方向(替代原始梯度),用 作为逐参数的学习率缩放因子。最终更新公式大致是:
但有个关键问题:在训练的最初几步, 和 都被初始化为零。由于指数移动平均的性质,前几步的值会严重偏向零,导致参数更新过小。Adam 使用偏差修正 Bias Correction来解决这个问题。
# 原理
第一步:更新一阶矩和二阶矩
第二步:偏差修正
偏差修正的直观理解:在 t=1 时,(注意 ),除以 后正好还原为 。随着 t 增大, 趋近于 1,偏差修正逐渐失效——这正是我们想要的,因为移动平均本身已经足够准确了。
第三步:参数更新
推荐超参数(论文默认值,大多数场景直接使用即可):
| 参数 | 推荐值 | 说明 |
|---|---|---|
| (lr) | 1e-3 | 学习率,有时用 5e-4 |
| 0.9 | 一阶矩衰减率(动量项) | |
| 0.999 | 二阶矩衰减率(缩放项) | |
| 1e-8 | 数值稳定常数 |
# AdamW:解耦权重衰减
标准 Adam 的一个隐性问题:当使用 L2 正则化时,正则化项的梯度进入了 和 的计算,导致权重衰减效果被自适应学习率干扰——不同参数的权重衰减强度不一致,违背了正则化的初衷。
AdamW(Loshchilov & Hutter, 2019)的解决方案极其简单:将权重衰减从梯度计算中解耦出来,作为独立的更新步骤:
最后一项 是直接的权重衰减,不经过任何自适应缩放。这个简单的修改在 ImageNet 等大型实验中一致地提升了泛化性能。AdamW 已逐渐成为现代深度学习训练的首选优化器。
# 代码实现
def adam(X, y, W_init, learning_rate, beta1, beta2, batch_size, num_epochs, eps=1e-8):
"""
Adam 优化器
beta1: 一阶矩衰减率,默认 0.9
beta2: 二阶矩衰减率,默认 0.999
"""
N = X.shape[0]
W = W_init.copy()
m = np.zeros_like(W) # 一阶矩(动量)
v = np.zeros_like(W) # 二阶矩(RMSProp cache)
t = 0 # 时间步计数
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
t += 1
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
scores = X_batch.dot(W)
loss, dW = svm_loss(scores, y_batch)
# 更新一阶矩和二阶矩
m = beta1 * m + (1 - beta1) * dW
v = beta2 * v + (1 - beta2) * (dW ** 2)
# 偏差修正
m_unbiased = m / (1 - beta1 ** t)
v_unbiased = v / (1 - beta2 ** t)
# 参数更新
W -= learning_rate * m_unbiased / (np.sqrt(v_unbiased) + eps)
loss_history.append(loss)
return W, loss_history
def adamw(X, y, W_init, learning_rate, beta1, beta2,
weight_decay, batch_size, num_epochs, eps=1e-8):
"""
AdamW 优化器:将权重衰减从自适应学习率中解耦
weight_decay: 权重衰减系数(即原 L2 正则化的 lambda)
"""
N = X.shape[0]
W = W_init.copy()
m = np.zeros_like(W)
v = np.zeros_like(W)
t = 0
loss_history = []
num_iters_per_epoch = N // batch_size
for epoch in range(num_epochs):
idx = np.random.permutation(N)
X_shuffled = X[idx]
y_shuffled = y[idx]
for i in range(num_iters_per_epoch):
t += 1
start = i * batch_size
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
# 注意:梯度计算中不包含 L2 正则化项
scores = X_batch.dot(W)
loss, dW = svm_loss_without_reg(scores, y_batch)
m = beta1 * m + (1 - beta1) * dW
v = beta2 * v + (1 - beta2) * (dW ** 2)
m_unbiased = m / (1 - beta1 ** t)
v_unbiased = v / (1 - beta2 ** t)
# 自适应更新 + 解耦的权重衰减
W -= learning_rate * m_unbiased / (np.sqrt(v_unbiased) + eps)
W -= learning_rate * weight_decay * W # 独立的权重衰减步骤
loss_history.append(loss)
return W, loss_history# 优化器对比总结
| 方法 | 动量/惯性 | 自适应学习率 | 偏差修正 | 核心特点 |
|---|---|---|---|---|
| SGD | ✗ | ✗ | ✗ | 最基础、最朴素 |
| SGD+Momentum | ✓ | ✗ | ✗ | 惯性冲过鞍点,平滑噪声 |
| RMSProp | ✗ | ✓ (EMA) | ✗ | 逐参数自适应,解决病态条件 |
| Adam | ✓ | ✓ (EMA) | ✓ | 动量 + 自适应 + 偏差修正,全能选手 |
| AdamW | ✓ | ✓ (EMA) | ✓ | Adam + 解耦权重衰减,泛化更好 |

# 学习率调度策略 Learning Rate Scheduling
学习率 不一定在整个训练过程中保持不变。一个好的学习率调度策略往往能显著提升最终性能。
# 常用策略
阶梯衰减 Step Decay:在预设的 epoch 节点将学习率乘以一个衰减因子(如 0.1)。例如 ResNet 在 epoch 30、60、90 各衰减一次。这是 CNN 时代的标准做法。
余弦退火 Cosine Annealing:
学习率沿着余弦曲线平滑地从初始值衰减到零。目前是 Transformer 和大模型训练的主流选择。
线性衰减 Linear Decay:
简单稳定,适合中小规模模型。
线性预热 Linear Warmup:在训练刚开始的若干步(通常前 5-10 个 epoch),将学习率从 0 线性增加到目标值。这防止了随机初始化的权重在最初几步产生过大的梯度导致训练不稳定。
# 实践建议
- 默认选择:AdamW + 线性预热 + 余弦退火衰减,这是 2025 年深度学习社区的主流方案
- 备选方案:如果计算资源充裕且需要极致性能,可以尝试 SGD + Momentum + 精心调参(学习率、动量、衰减策略),在一些大规模视觉任务上仍有超越 Adam 的可能
- 经验法则:batch size 翻倍时,学习率也翻倍(线性缩放法则)
- 不要过早优化:先用固定学习率观察 loss 曲线,确定模型能正常训练后再加入衰减策略

# 声明
本blog由Yumengmeng基于2025春季李飞飞斯坦福CS231n计算机视觉课程的视频内容结合Claude Code抓取网上开源笔记进行美化与排版,仅供个人复习使用。