
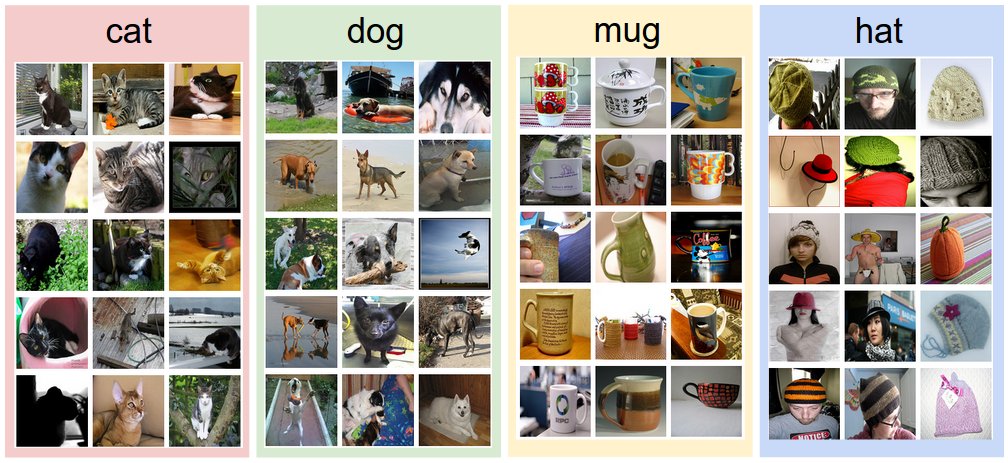
# 图像分类 Image Classification
图像分类的核心任务:给定一张图像和一组类别标签,设计算法将其中一个标签分配给此图像。
图像在计算机中就是一个巨大的数字网格,每个像素值介于 [0,255] 之间。对于一个 800×600 分辨率的彩色图像,其数据张量为 800 × 600 × 3,因为有 RGB 三个颜色通道(红、绿、蓝)。
语义鸿沟 Semantic Gap:人类看到图像能轻松识别物体,但计算机看到的只是一个巨大的整数矩阵。这个差距就是我们需要跨越的核心问题。
- 图像分类面临的六大挑战:
- 视角变化 viewpoint variation:即使物体完全静止,只要相机视角发生微小变化,数据张量就可能完全不同
- 光照条件 illumination conditions:RGB 像素值是表面材料颜色与光源共同作用的函数,同一物体在不同光线下数值差异巨大
- 形变 deformation:物体本身具有非刚性,姿态变化导致像素分布改变
- 遮挡 occlusion:物体被部分遮挡,人类可以通过部分信息做出精确判断,计算机则非常困难
- 背景杂乱 background clutter:物体与背景混杂在一起,难以分离前景和背景
- 类内变化 intraclass variation:同一类别内的个体差异本身就很大(比如不同品种、不同颜色的猫)
传统的基于边缘检测器的方法(找到图像边缘 → 提取特征 → 映射成输出类)效果有限,无法应对这些复杂性。
数据驱动方法 Data-driven approach 的核心思路:
- 收集足够多的图像及其标签的数据集
- 使用机器学习算法训练分类器——用训练函数接受图像与标签,建立一个将图像与标签关联的模型
- 在新的图像上测试分类器——创建预测函数,输入测试图像,预测标签并返回
def train(images, labels):
# 记忆数据与标签
return model
def predict(model, test_images):
# 为测试图像找到最相近的训练图像,输出该图像标签
return test_labels# 最近邻分类器 Nearest Neighbor Classifier
最简单的数据驱动方法:记住所有训练数据,预测时在训练集中找到与测试图像最相似的一张,输出其标签。
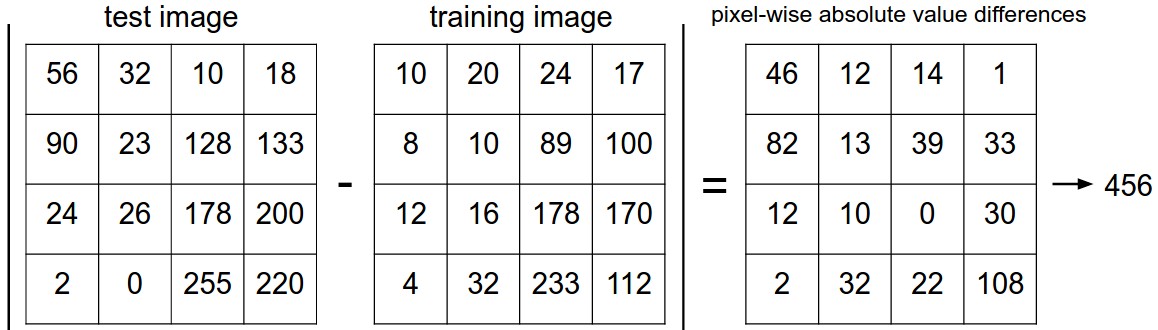
我们需要一个距离函数来衡量两张图片的相似程度。
L1 距离(曼哈顿距离 Manhattan Distance):
对每个像素位置 p,直接求像素差的绝对值并累加。如果两张图完全一样,L1 距离为零;差异越大,距离值越大。
L2 距离(欧氏距离 Euclidean Distance):
L2 是几何意义上的直线距离。
完整的 Nearest Neighbor 分类器实现:
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
"""训练就是记住所有训练数据,只需 O(1) 时间"""
self.Xtr = X
self.ytr = y
def predict(self, X):
"""预测:对每个测试样本,遍历训练集找到最近邻"""
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
# 使用 L1 距离:广播计算测试样本与所有训练样本的差值
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
# 找到距离最小的训练样本索引
min_index = np.argmin(distances)
# 输出该训练样本的标签
Ypred[i] = self.ytr[min_index]
return Ypred这个分类器的设计哲学是:训练快(O(1)),预测慢(O(N))。但实际应用中我们恰好需要相反的特性——可以接受训练慢一些,但预测必须快,因为用户不会等。
- L1 与 L2 距离的关键区别:
- L1 距离对特征值敏感:它的决策边界几乎平行于坐标轴,对图像的旋转会导致 L1 形状变化
- L2 距离对特征值不敏感:它的决策边界不受坐标轴方向限制,旋转图像后 L2 看不出变化
- 实际选择取决于特征向量中每个维度的含义——如果各维度有明确的物理意义,L1 可能更好;如果只是通用空间向量,L2 更合适

# K-邻近算法 K-Nearest Neighbor
最邻近算法可以自然地扩展为 K 邻近算法:选择距离最近的 K 个邻居进行多数投票,票数最多的类别作为预测结果。
- 当 K > 1 时,决策边界变得更平滑,对噪声和离群点更鲁棒
- 图中白色区域是 K 个邻居中平票的区域,无法确定标签——说明这个区域数据不足,适合收集更多数据
在 CIFAR-10 数据集上(10 个类别,50000 张训练集,10000 张测试集),KNN 的准确率约为 28%~29%,仅比随机猜测(10%)好一些。
超参数 Hyperparameters 是由用户设定的变量(如 K 值、距离函数的选择),模型无法从数据中自动学到。如何选择超参数是机器学习中的关键问题。
- 四种超参数设置策略(递进式推理):
- ❌ 选择在训练集上表现最好的超参数:模型会"记住"训练数据,训练准确率始终接近 100%,但严重过拟合,无法泛化到新数据
- ❌ 选择在测试集上表现最好的超参数:这是"作弊"行为——测试集信息泄露到超参数选择中,我们无法知道算法在新数据上的真实表现
- ✅ 将数据分为训练集 train、验证集 validation、测试集 test:在训练集上用不同超参数训练,在验证集上评估并选出最佳超参数,最后仅在测试集上运行一次得到最终结果。测试集是一种极其宝贵的资源,在最后一步之前永远不要碰它。这个方法的难点在于需要选择合适的验证集划分
- ✅ K-Fold 交叉验证 Cross-Validation:将训练数据折叠成 K 个褶皱,每个褶皱轮流充当一次验证集,其余 K-1 个做训练集。训练 K 次后取平均精度。最后用最佳超参数在全部训练数据上重新训练,在测试集上评估一次。这可以产生更可靠的结果,但在大数据集上计算负担很重,深度学习实践中不常用
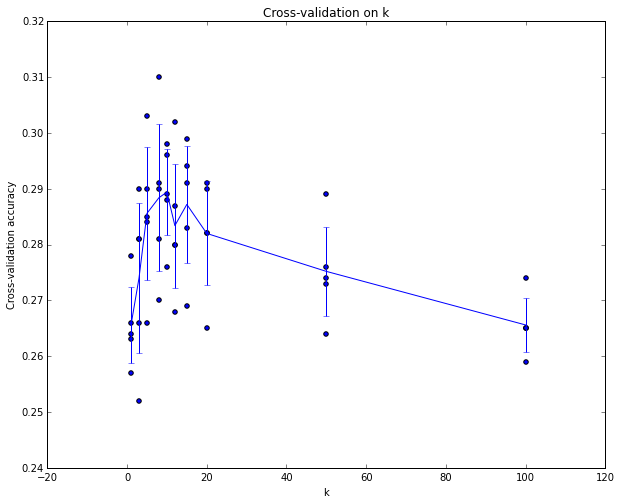
# 交叉验证示例:在 CIFAR-10 上为 KNN 寻找最佳 K 值
# 假设 Xtr_rows 和 Ytr 是训练数据
Xval_rows = Xtr_rows[:1000, :] # 取前 1000 个作为验证集
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # 剩余作为训练集
Ytr = Ytr[1000:]
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# 对每个 k 值评估验证集精度
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yval_predict = nn.predict(Xval_rows, k=k)
acc = np.mean(Yval_predict == Yval)
validation_accuracies.append((k, acc))实验结果表明 CIFAR-10 上最优 K 值约为 7。

KNN 的三大缺陷:
- 预测时间极慢:训练 O(1),预测 O(N),与实际需求完全相反。我们关注的是测试效率,用户不会为了分类一张图片等上几分钟
- 像素距离不等于语义距离:从人眼来看四张完全不同的图片,它们的 L2 像素距离可能完全相同——背景、姿态、光照的不同导致逐像素比较彻底失效
- 维度灾难 Curse of Dimensionality:在高维空间中,距离的概念变得反直觉——所有点看起来都很远,最近邻失去意义。要密集覆盖高维空间,所需样本数以指数级增长
但 KNN 仍然是一个理解数据驱动方法和超参数调优的绝佳起点。
# 线性分类器 Linear Classifier
线性分类器是整个神经网络和卷积网络的基础构件。大规模神经网络实质上就是这些基础单元一层层堆叠起来的。
# 核心公式
- x:输入图像,展开为列向量。CIFAR-10 图像为 32×32×3 = 3072 维
- W:权重矩阵 Weights,又称为参数。输出是 10 个类别的得分,所以 W 的维度为 10 × 3072
- b:偏置向量 Bias,维度为 10 × 1,表示数据独立的类别偏好值(例如数据集中猫的图像比狗多,则猫对应的偏置会更大)
- f(x, W):输出是一个 10 维向量,每个元素对应一个类别的得分 score
W 的每一行对应一个类别的分类器。线性分类器的几何本质是:在 3072 维空间中找到一个超平面,将不同类别区分开来。
如果没有偏置 b,每条分界线都必须穿过原点,分类将失去灵活性——比如当某个类别的所有样本都落在第一象限时,穿过原点的直线无法很好地分离它们。
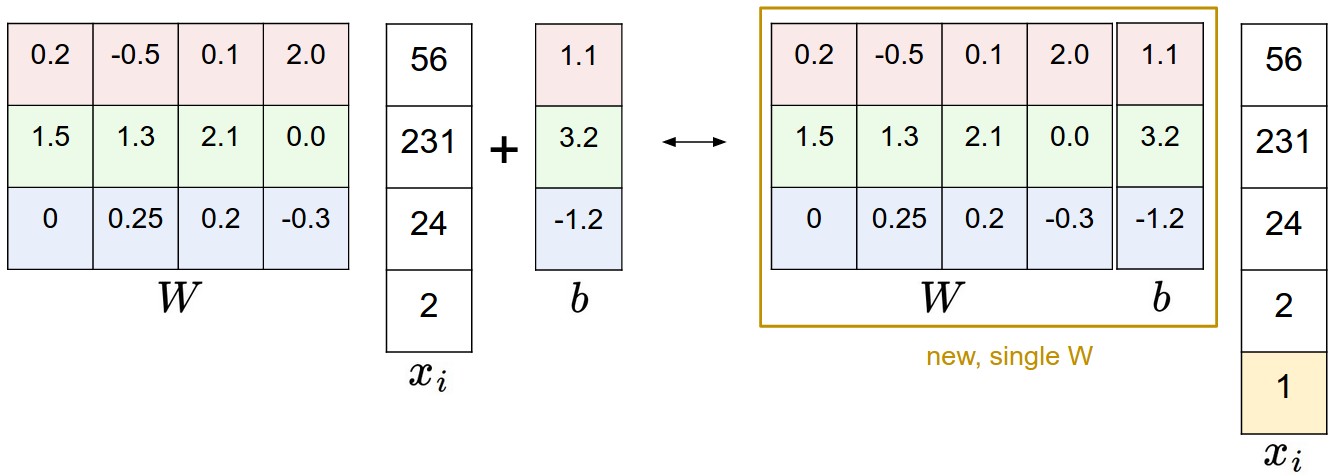
# 技巧:将 W 和 b 合并
在 x 向量的末尾添加一个常数维度 1,同时将 b 作为新的一列附加到 W 中:
这样公式更简洁,实现时也更方便。
# 模板匹配视角 Template Matching
线性分类器还可以从另一个角度理解:
- W 的每一行可以重新排列成与输入图像相同的大小(32×32×3),想象成一张"模板"图像
- 线性分类就是使用内积来比较输入图像与每个类别的模板,找到最相似的那个
- 以船分类器为例:蓝色通道(水和天空)有许多正权重,而红色和绿色通道多为负权重——这恰好是一张蓝色大海背景下船只轮廓的模糊模板

# 图像预处理
在输入分类器之前,建议将像素值从 [0, 255] 归一化到 [-1, 1] 范围,有助于训练稳定。
# 线性分类器的局限性
线性分类器每类只能学习一个模板,无法处理多模态数据。以奇偶像素计数分类为例:蓝色类别在平面上占据两个相反的象限——没有办法绘制一条单独的直线来同时覆盖两个离散的蓝色区域。
以下三类问题线性分类器无法解决:
- 奇偶问题(类别按奇偶数分布在两个相反的象限)
- 同心圆问题(内外圆分属两类)
- 多模态分布(同一类分布在空间中不相邻的多个区域)
这些局限正是后续引入神经网络和非线性激活函数的原因。
# 损失函数 Loss Function
现在的问题是:如何量化 W 的好坏? 损失函数用于衡量分类器的"糟糕程度"。我们的目标是找到一个 W 使得损失函数值最小。
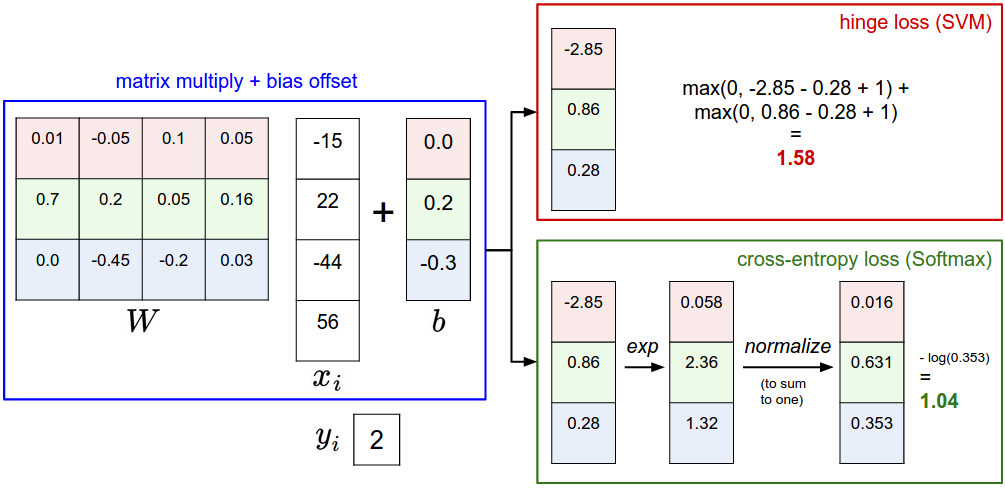
# 多分类 SVM 损失 Multiclass SVM Loss(Hinge Loss)
- :正确类别的得分
- :错误类别的得分
- :安全间隔 margin,通常取 1
直观理解:我们希望正确类别的得分比所有错误类别高出至少 。如果某个错误类别的得分与正确类别差距小于 ,则产生损失;如果差距足够大(大于 ),则损失为零。这个损失被称为 Hinge Loss,因为它的形状像合页一样在 处弯折。

# Softmax 分类器(交叉熵损失 Cross-Entropy Loss)
将得分转化为概率分布:
- 指数化:取 ,确保所有值 > 0
- 归一化:除以所有指数之和 ,使所有概率之和为 1
例如模型输出 [cat: 0.13, car: 0.87, frog: 0.00],意味着模型认为这张图是猫的概率为 13%,是车的概率为 87%,是青蛙的概率为 0%。
损失函数直接取负对数似然 Negative Log Likelihood:
本质是在做最大似然估计 Maximum Likelihood Estimation——我们希望正确类别的概率越大越好。
# 交叉熵与 KL 散度的关系
- P 是真实概率分布,Q 是模型预测的概率分布
- H(P) 是真实分布的熵(常数,真实标签固定不变)
- 交叉熵 = KL 散度 + 常数,所以最小化交叉熵就是在最小化 KL 散度,让预测分布逼近真实分布
# 两个实用的 Debug 问题
Q1:Softmax 损失函数的最大值是多少?
理论上为无穷大。当正确类别的概率趋近于 0 时,。实际中由于数值精度限制,概率不会精确为零,但可以非常大。
Q2:初始化时所有权重为小随机数,所有 近似相等,损失函数的值是多少?
所有类别概率相等,:
当 C = 10 时,。这是一个很有用的 sanity check:训练刚开始时如果 loss 偏离这个值太多,说明实现中很可能有 bug。
# 正则化 Regularization
完整损失函数 = 数据损失 Data Loss + 正则化项 Regularization:
- 数据损失:让模型拟合训练数据,最小化预测误差
- 正则化项:惩罚复杂模型,鼓励简单权重,防止过拟合
- :平衡两个目标的超参数
常见的正则化方式:
- L2 正则化:,鼓励权重分散到所有维度,惩罚个别过大的权重值
- L1 正则化:,鼓励稀疏权重
- Elastic Net:L1 + L2 的结合
# 声明
本blog由Yumengmeng基于2025春季李飞飞斯坦福CS231n计算机视觉课程的视频内容结合Claude Code抓取网上开源笔记进行美化与排版,仅供个人复习使用。